Funded Research Projects
Decentralized and Distributed Deep Learning for Industrial IoT Devices
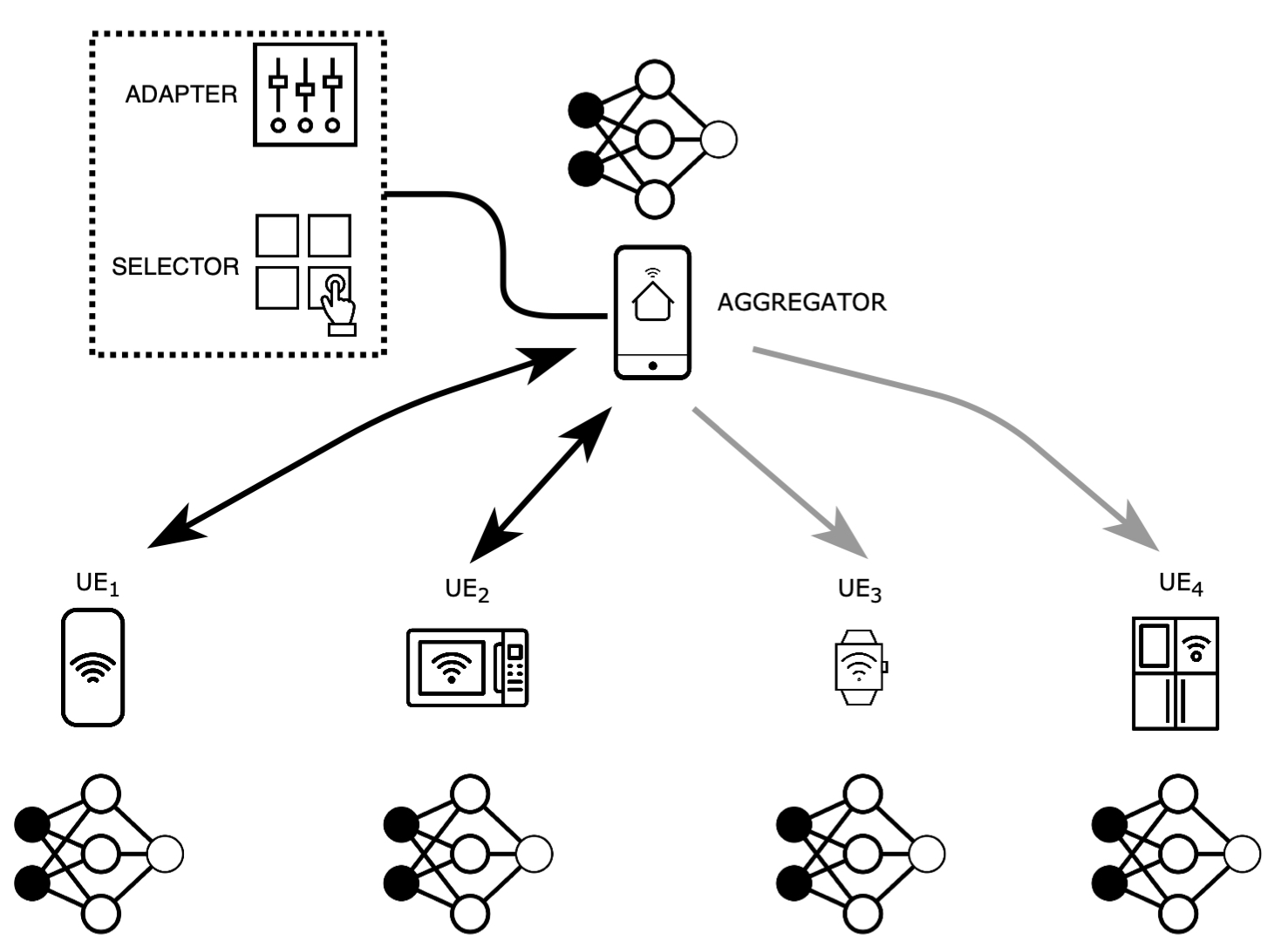
Different from conventional model training that needs to collect all the user data in centralized cloud servers, federated learning has recently drawn increasing research attention: decentralized edge devices train their model copies locally over their siloed datasets and periodically synchronize the model parameters. However, model training is computationally extensive which easily drains the battery of mobile devices. In addition, due to the uneven distribution of siloed datasets, the shared model may become biased. This project (funded by CVDI IAB) addresses such critical concerns of efficiency and fairness in a resource-constrained federated learning setting.
Precise Regional Forecasting via Intelligent and Rapid Big Data Harness
This multidisciplinary project (funded by NSF, OIA-2019511) with jurisdictional collaboration addresses precise regional forecasting via intelligent and rapid harness on national scale hydrometeorological Big Data, for better numerical models on weather and climate parameters to improve forecasting accuracy.
Our group works in collaboration with the other involved EPSCoR jurisdictions and the U.S. Geological Survey (USGS), for the major thrusts of deep learning based regional forecasting and the acceleration of model training.
Fast and Efficient Scheduler for Deep Learning in GPU Cluster
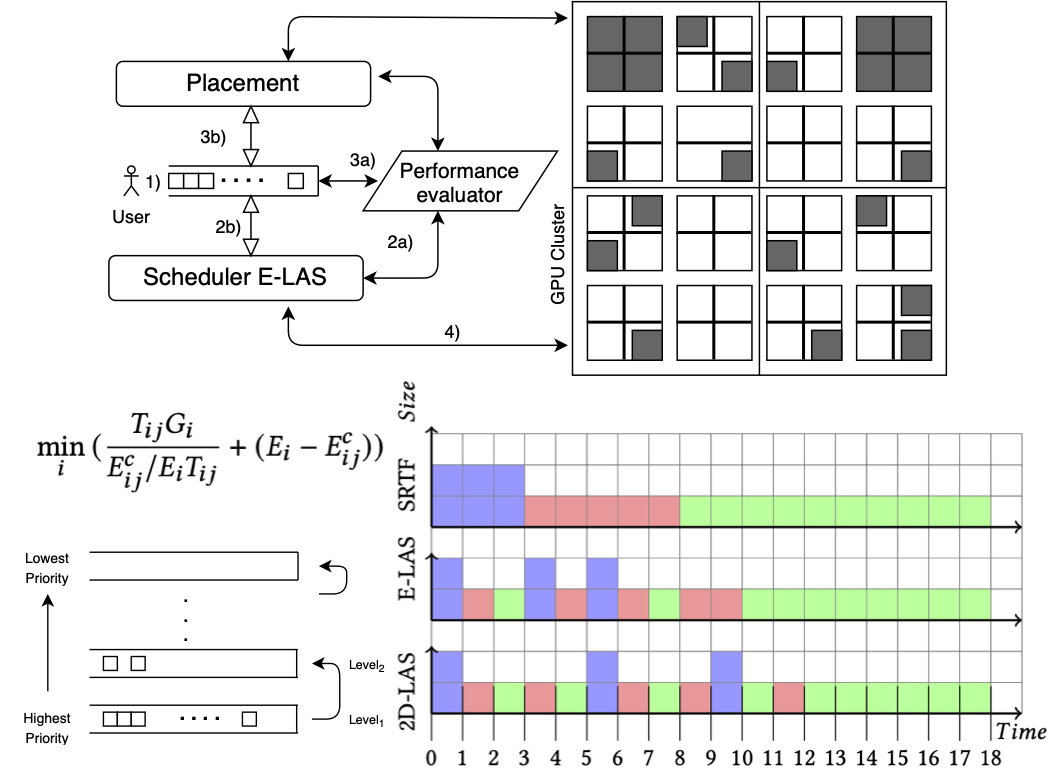
This project (funded by BoRSF PoC/P) aims to facilitate high-performance distributed deep learning by the design and prototyping of a fast and efficient scheduler for a GPU cluster that manages and coordinates resource allocation among deep learning jobs. The proposed research activities include designing, fine-tuning, and implementing the strategies of job scheduling and task placement in the prototype GPU cluster scheduler, guided by the theoretical foundation of the scheduling algorithm. Economic benefits are expected, because the jobs become faster to serve requests timely and the cluster is utilized more efficiently to save the operation cost.
Smart Optimization Framework to Accelerate Distributed Deep Learning
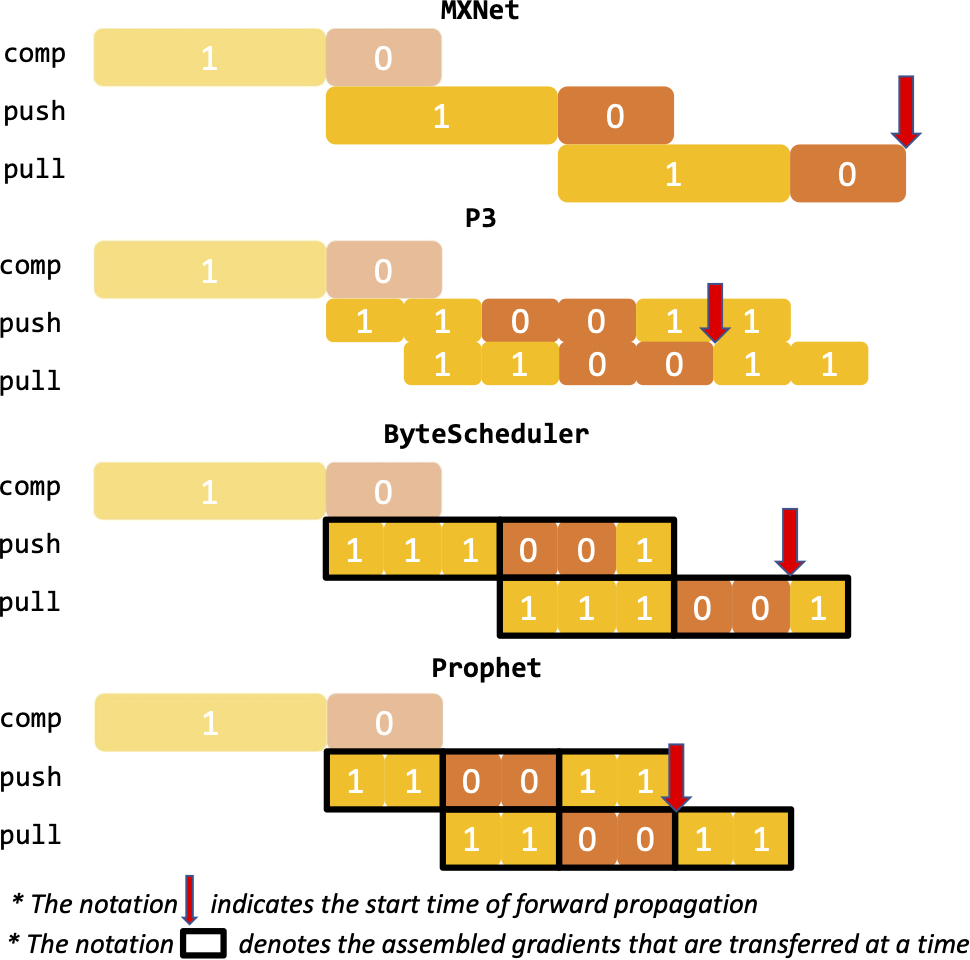
Training deep neural networks for various AI tasks can take days or weeks on a single machine, which drives the demand of scaling out to a cluster of machines for distributed learning. Although faster hardware (GPUs) and more machines provide promising computational power for scaling up, the performance of training time is bottlenecked by the network communication when parameters at each machine need to be synchronized over the cluster. This project (funded by BoRSF RCS) seeks to alleviate the communication bottleneck and accelerate distributed deep learning by the design and integration of cross-layer strategies into a unified judicious optimization framework, to better accommodate the ever-increasing deep learning demand.
More project works are to come …